- Home
- Learn Linux
- Learn Electronics
- Raspberry Pi
- Programming
- Projects
- LPI certification
- News & Reviews

Google Ads
This reference guide will discuss the basics of TCP/IP networking. Although intended for an audience of Linux users and administrators, the contents of this will apply equally to other operating systems or networking devices. A future tutorial will provide the specific commands and files which provide the configuration on Linux systems.
Although there are other types of network this guide will only cover TCP/IP networking. With the success of the Internet this is the dominant protocol in use almost exclusively today.
This is primarily aimed at the current IP Version 4, although an introduction to IP Version 6 is included. A shortage of remaining IPV4 addresses is encouraging a more agressive push towards IPV6 over the next few years.
TCP/IP is an abbreviation for Transmission Control Protocol / Internet Protocol. It is a set of protocols that define how two or more computers can communicate with each other. The protocol is effectively a set of rules that describe how the data is passed between the computers. It is an open standard so can be implemented on any computer with the appropriate physical attributes. Within the TCP/IP networking protocol there are lots more protocols. These provide different functionality important to the exchange of data over the networks. These can be integral to the operation of the networking, such as the Domain Name System or could be an application that uses the network such as E-mail (both of these are discussed in further detail later).
Another related protocol is UDP (User Datagram Protocol) which also runs on top of the IP (Internet Protocol). The difference between TCP and UDP is that TCP is connection based protocol whereas UDP is connectionless. In other words when TCP is being used there is a session setup between the hosts and the transfer is guaranteed. For UDP each data packet is sent but there is no checking that it has been received, or anyway of resending within the network layers. An application can run on top of UDP and implement it's own checking that each packet is received, but that is not the same as leaving it to the networking stack to implement.
A common way of comparing these is to liken TCP to the telephone system and UDP to the postal service. With the telephone when you establish a connection with the other person, you know for certain that the user receives the message. If you were disconnected during the telephone conversation then you would know about it and be able to phone the other person again. With the postal system after you post the letter then you do not know for certain whether or not the mail will be received. After you have posted the letter it could be lost or destroyed on it’s way to it’s destination. Or if the person has moved house they may never receive the letter.
At first it may sound that there is no reason to choose UDP over TCP after all if you can have the extra reassurance then why would you care about UDP. The reason for this is that there is a lot of overhead involved in TCP. For each data packet being sent a confirmation has to be generated and even if there is no data being sent there will often be some kind of keep alive signal. Whereas for some less important data you may just want to send and forget it with the hope it will reach the other end. It's also possible for the sesssion to be handled higher up the networking stack (but I'm getting ahead of myself here).
Networking protocols are often described relating to the OSI model. This is a model to describe the different networking functionality by the Open Standards Institute. The OSI model splits the different functions of networking into different layers. By describing the networking protocols in layers it allows the layer to be changed without affecting other layers. For example when using a different physical connections (e.g. fibre rather than copper), then different signals need to be sent over the cable, but as long as it interacts in the same way with the layers above it then it can still function.
The networking models are particularly useful in that it allows the protocol to be implemented on any system. Allowing UNIX computers to talk as a peer with windows computers or mainframes.
| 7 | Application |
| 6 | Presentation |
| 5 | Session |
| 4 | Transport |
| 3 | Network |
| 2 | Data link |
| 1 | Physical |
Figure 1: OSI 7-Layer Model
The above diagram shows the 7 layer model. Starting from the bottom the function of the layers is as follows:
Physical Layer - describes the media over which the data travels. For instance this describes the voltage of a 1 or 0 signal across a copper wire.
Data Link Layer - describes the means by which the bits are carried across the physical layer. For example this can describe how the start and end of a data stream is indicated.
Network Layer - this layer handles the routing of data through a network. As an example this describes how routing can happen based upon the address of the computers.
Transport Layer and Session Layer - the transport and session layers provide end-to-end session integrity. This includes keep alives to ensure the connection is maintained.
Presentation Layer and Application Layer - These provide the interface to the application. For example this may include the use of the nslookup command to convert a hostname into an IP address.
Whilst the TCP/IP protocol does not exactly match the OSI 7 layer model it can be approximately mapped across onto it. The following diagram shows the TCP/IP stack compared with the OSI 7 layer model.
| OSI model | TCP/IP stack | |
|---|---|---|
| 7 | Application | Application |
| 6 | Presentation | |
| 5 | Session | TCP or UDP |
| 4 | Transport | |
| 3 | Network | IP |
| 2 | Data link | Network interface |
| 1 | Physical | Physical |
Figure 2: TCP/IP Stack Alongside the OSI 7 Layer Model
This model shows how the TCP/IP protocols are mapped onto the 7-layer model. Note that the application and presentation layers have been merged and that the session and transport layers have been merged. The distinction between these layers are not needed in the TCP/IP model. There is an exception in the NFS application in that it sits on top of the SUN RPC protocol which functions as a presentation layer, however for most purposes they are considered as a single layer. Also the borders between the layers are not as rigidly defined in the TCP/IP as in the OSI model and the functions are not neccessarily a direct match between the OSI model.
Knowing the layers of the network model can however be useful when trying to pin down a certain problem. If you can determine that connectivity is working at a certain level within the stack then you can restrict future investigations to the remaining areas.
TCP/IP was originally developed for universities and the military to exchange ideas and files. The development of TCP/IP is initiated by the Internet Architecture Board (IAB), and the development of standards is handled by the Internet Engineering Task Force (IETF). The documents produced by the IAB are called Request For Comments (RFC) which describe the protocols and relevant information useful for the implementation. Anyone can submit a document as an RFC which are reviewed before being published as official RFC’s. After an RFC is published and assigned an RFC number is its never revised under the same number. Instead a new RFC must be created which supersedes the previous version.
An important part of all networking protocols is the addressing scheme. Without being able to locate the individual machines (or hosts as they are called) then it would not be possible for any communication between the hosts. There will be more than one addressing scheme in use but the most important of these is the Internet Protocol (referred to as IP), this is significant as it provides the addressing for each end of the connection. The other addressing schemes are effectively hidden from the user at layers two or below and are automatically handled by the networking hardware. The current version of IP is called IP version 4 but will be replaced by IPV6 in future. When I refer to IP it refers to version 4 unless otherwise specified.
The addresses used in the Internet Protocl consist of four octets and is 32 bits long. The address is stored in a format known as dotted decimal.
ie.xxx.xxx.xxx.xxx
where xxx is a number between 0 and 255.
So an example IP address may be: 192.168.3.27
Most users however would not actually need to use the IP address. Instead they would refer to the computer using it’s host name. The IP address is obtained from the host name using the "Domain Name System" (DNS). There is no actual relationship between the hostname and the IP address instead this uses a lookup table. The Domain Name Service will be discussed later.
The IP addressing scheme provides 232 possible addresses, which could potentially have over 4.2 thousand million individual addresses. The problem with this however is that trying to locate each one of those addresses individual over the Internet would be an enormous task. So instead the address is split into a network and a host portion. The idea being that different organisations can be assigned a network which can have between 256 and 16.7 million addresses available for hosts. The address range now allows up to 3.7 thousand million hosts on 2.1 million networks.
To accommodate for different sized organisations which require a different number of host addresses, the addresses are split into different network classes. There are 5 different classes however only 3 are commonly used.
Class A - These are for large organisations. The network portion is 8 bits long and begins with binary 0. There are 126 possible networks each with up to 16.7 million hosts.
Class B - These are for medium sized organisations. The network portion is 16 bits long and starts with binary 10. There are 16 thousand networks each with up to 65 thousand hosts. In reality the definition of a medium sized organisation would be a very large company
Class C - These are for smaller organisations. The network portion is 24 bits long and begins with binary 110. There are 200 thousand possible networks each with up to 254 hosts. In reality even these are quite large, so are often split further (see later).
Class D - These are allocated for multicast although are rarely used. The addresses begin with binary 1110.
Class E - These are experimental. The addresses begin with binary 1111.
| Class A | 0.hhh.hhh.hhh | to | 127.hhh.hhh.hhh |
| Class B | 128.nnn.hhh.hhh | to | 191.nnn.hhh.hhh |
| Class C | 192.nnn.nnn.hhh | to | 223.nnn.nnn.hhh |
| Class D | 224.xxx.xxx.xxx | to | 239.xxx.xxx.xxx |
| Class E | 240.xxx.xxx.xxx | to | 255.xxx.xxx.xxx |
Figure 3: IP address class ranges
In the above table the nnn represent the network portion of the address and the hhh represent the host portion of the address.
The observant, mathematically minded my have noticed that some of the numbers mentioned earlier appear to be incorrect. Some of these are through rounding down, but others are due to certain addresses being reserved for other uses.
| 127.0.0.1 | Refers to localhost |
| All host bits binary 0s | Refer to the network |
| All host bits binary 1s | Broadcast address - send to all addresses |
| Class A | 10.0.0.0 | to | 10.255.255.255 |
| Class B | 172.16.0.0 | to | 172.31.255.255 |
| Class C | 192.168.0.0 | to | 192.168.255.255 |
The private address ranges are for use internally within an organisation. They cannot be used on the Internet. To provide Internet access for a host with a private address range the communications have to go through a NAT (Network Address Translation). This is one way that the number of available IP addresses can be preserved.
Apart from the private address ranges all other IP addresses need to be registered with the InterNIC before they can be used.
The biggest problem with the IP addressing scheme is that it is rapidly running out of free addresses. The long term solution is to move from IP version 4 to IP version 6 which will provide 340,282,366,920,938,463,463,374,607,431,768,211,456 separate addresses. This should provide for all the Internet will ever need, even if every electronic device is given its own IP address. In the meantime a method was needed to make better use of the addresses available under the IP version 4 scheme.
One of the problems with the current addressing is that the addresses are given away in large chunks. Subnetting allows these large chunks of addresses to be further split into a further network and host component. This new network component is called the subnet.
The following shows how a class B network address could effectively split into 254 separate virtual class C networks:
nnn.nnn.sss.hhh
nnn = network portion of the address
sss = subnet portion of the address
hhh = host portion of the address
The network portion has been fixed so still stands as the first two octets. The next octet which would normally be part of the host address is then made to signify the subnet and effectively becomes part of the network address. The final octet is left as the host portion of the address.
If we change which part of the address represents the network and host then we need to tell the computer and any routing devices of that. The technique used is known as creating a subnet mask.
The subnet mask for the above example would be 255.255.255.0 as we can see this is in a similar format to the IP address. To explain how this is derived requires a little bit of binary arithmetic. I will attempt to briefly explain how this works, however am unable to devote a large section to it. If you need further explanation then there are a number of different books purely devoted to TCP/IP most of which spend a considerable effort in explaining the concept of subnetting.
Whilst an IP address is generally represented as decimal numbers to make it easier for people to understand, however the computer works on binary numbers which can only represent one or zero. For example the following address shown as dotted decimal and binary.
| 172 | . | 16 | . | 3 | . | 4 |
| 10101100 | 00010000 | 00000011 | 00000100 |
As you can see writing this as binary every time would be very tedious and prone to errors.
To create a subnet mask we need to use a binary one for every bit of the address that represents the network portion and a binary zero for any bit of the address that represents the host portion.
This gives us:
11111111 11111111 11111111 00000000
We convert this to decimal to make it easier to read and it gives us a subnet mask of
255 . 255 . 255 . 0
Using simple binary arithmetic the computer can use the subnet mask to convert the IP address into it’s network and host portion. It would use a binary AND to get the network portion. To get the host portion the subnet mask is inverted (NOT function) and then AND’d against the IP address.
Just to confuse matters further some equipment (e.g. Cisco routers) use a different notation to represent the subnet mask. The would count in the number of '1' bits and give that as the subnet mask number. So in this example the subnet mask would be represented as /24. This is referred to as the CIDR notation.
The example above showed the subnet mask on a octet boundary however it is more common to see a subnet mask within an octet. For example the subnet mask 255.255.255.248 might be used to split a class C network address into 30 subtends each with 6 hosts.
The expanded mask would be:
11111111 11111111 11111111 11111000
Taking only the last eight bits the host portion is
11111 This potentially can have 32 subtends excluding reserved addresses (all ones and all zeros) gives 30 valid addresses.
The network portion is
000 This potentially can have 8 hosts excluding reserved addresses (all ones and all zeros) gives 6 valid addresses.
The subtends are given a number which is when all the host portion are zero. All the rest of the addresses are valid until the part where all the host bits are ones which is the broadcast address for that subnet.
Looking at only the last octet the following table shows how some of the address will be made up.
| Subnet Number | First Address | 2nd address | ... | Last address | Broadcast |
|---|---|---|---|---|---|
| 8 | 9 | 10 | ... | 14 | 15 |
| 16 | 17 | 18 | ... | 22 | 23 |
| 24 | 25 | 26 | ... | 30 | 31 |
To try and understand this better convert the values in binary and then identify the host and network portions of the address.
Whilst I have excluded the 0 address it is sometimes possible to actually use this. For this you may have to ensure that your routers support this and that the feature is turned on. It is however not recommended.
A alternative subnet mask could be 255.255.255.224 which would give 6 valid subs each having a maximum of 30 hosts (this could be useful for splitting up a smaller company which might have 6 different LAN segments with up to 30 machines on each). You may find it a useful exercise to try and calculate these values for yourself.
The opposite of subnetting is called supernetting. instead of dividing network ranges into subtends a number of subtends are joined together to make a supernet. The class A and B network ranges have been all but used up and so instead several class C networks are grouped together for larger organisations and ISP's.
You can view the IP Subnet Table Quick Reference
Whilst the IP address provides the connection to the correct machine, it cannot distinguish the different service that is required. The port is used to distinguish the application. It is a value from 0 to 65535. The combination of IP address, port and protocol is called a socket, and has to be unique for every service. The port numbers area available for both TCP and UDP, and when referred to in conjunction with the IP address it specifies the "socket".
The first 1000 ports are reserved for specific applications, and on Linux can normally own be used by a daemon / application that has super user privileges. These are referred to as well known ports. Some are defined in RFC 1340, and more are defined by IANA.
Details of the reserved ports are listed on most linux systems in the /etc/services file.
Some of the common ports are:
20 & 21 FTP 23 Telnet 25 SMTP (Simple Mail Transfer Protocol) 53 DNS 80 World Wide Web 110 POP3 (Post Office Protocol) 144 News 6000 X-Windows
Ports above 1000 can be used for any other purposes.
Also see: TCP and UDP Port Numbers (/etc/services) Quick Reference
There are other addressing protocols used. These are at lower levels of the protocol stack and differ depending upon the media being used. The most commonly used of these is the MAC (Media Access Control) address. The ARP Protocol (Address Resolution Protocol) is used to allow IP addresses to be translated into MAC addresses. The following diagram is used to show how this works.
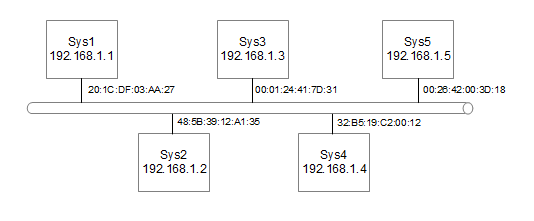
Figure 4: Diagram of Ethernet with MAC addreses
Down at the lower levels the physical ethernet connection does not know anything about IP addressing. The IP addressing occurs at layer 3 which is higher than Layers 1 and 2 that ethernet works at. Instead they use a MAC address which consists of 6 numbers separated by colons. This allows different networking protocols to be carried over ethernet such as SNA (Used by IBM Mainframes) or IPX (formally the default addressing scheme used by Novel Netware).
The MAC address is usually hard coded into the ethernet card and are unique across every device made. This is achieved by allocating a block of addresses to each manufacturer of ethernet devices. Normally the user would not know or care about the value of the MAC address as it is transparent to the user. It is sometimes possible to manually change the MAC address, but this is not advisable unless you have a specific requirement and know what you are doing.
To translate between IP addresses and MAC addresses on the local ethernet the Address Resolution Protocol (ARP) is used.
For example when system Sys1 wants to communicate with another such as Sys4 then the user would use its IP address 192.168.1.4. Now Sys1 needs to convert this address into the MAC address of Sys4. It therefore issues a MAC broadcast to all machines asking for the machine with IP address 192.168.1.4 to reply. Sys4 will reply with it's MAC address 32:B5:19:C2:00:12. Sys1 then adds the IP address and MAC address of Sys4 to its ARP table. Sys4 likewise knows the IP address and MAC address of Sys1 (as Sys1 included it's IP address in the original broadcast) so it adds that to its ARP table. Now in future when ever the systems want to communicate they just lookup the MAC address in the systems ARP table.
If the machine is not located on the same LAN then this requires IP routing which is explained later.
Whilst the IP addressing scheme allows computers to communicate with each other it's not particularly an easy way for people to remember. Which would you find easier to remember www.easytoremember.com or 172.16.35.122 ?
Hostnames have an hierarchical structure. The names read from right to left as though moving down a tree.

Figure 5: Example DNS tree
Take a few of these examples.
The final name of this computer (known as the fully qualified domain name FQDN) is mail.location1.companyname.com
The responsibility of dividing up all the names below the company name is owned by the end company or organisation. However the organisation domains obviously need to be allocated by a governing body to ensure that two companies don't try and use the same one. This is administered by local organisations dependant upon the top level domain. The top level domain names (TLDN) are allocated by IANA. The primary TLDNs are :
arpa - Used for DNS mapping
com - Commercial
edu - Educational
gov - Government
mil - Military
net - Network support groups or ISPs
org - Other organisations (normally charities)
int - International Organisations
There are also country top level domains that can be used for domains within countries, although note that there is no restriction on being located or working in that country . For example the top level domain for the United Kingdom is uk. Some examples are:
ac.uk - Academic Community (Education)
co.uk - Commercial
gov.uk - Government / Councils
ltd.uk - Limited Companies
org.uk - Other organisations (normally charities)
To explain DNS it's easiest to work through an example DNS request
.If a computer wants to communicate with www.penguintutor.com then it will first contact its local DNS server with an nslookup for that specific site. This will normally be a DNS server provided by their own company or their ISP. Their local DNS server does not know about the existence of the web site. That DNS server may then try asking the root DNS. This DNS does not know anything about the computer in question however it does now about the .com domain and returns details of the DNS servers that owns the domain (in the case of other country top level domains then it will respond with the DNS servers that own that country domain). The local DNS server will then contact one of the DNS servers for the .com domain which will return the DNS servers responsible for the penguintutor.com domain. When the local DNS server then contacts that server is does have the entries for that domain and can provide the specific ip address. In this case it is known as an authoritative answer as it is 100% certain that this is the IP address because it is responsible for that domain. The DNS server can then respond to the requestor with the IP address.
Another way is for one of the intermediate DNS servers to provide a recursive query, whereby it goes and queries another DNS server on behalf of the requesting DNS server. DNS servers do not have to support recursive queries, in which case the initial DNS server will need to perform the lookups itself.
This sounds like a very long process if it has to be carried out for every machine that is to be accessed. If this was the case then the load on the top level DNS servers would be excessive. To speed up the DNS process many DNS machines provide a caching feature where they can store the result of some of the lookups they perform. The names cached can either be for specific hosts (although except for popular sites they will be less likely to have a hit on the cache). Alternatively the DNS will cache the address of another DNS server allowing it to bypass some of the process (for example caching the com DNS would allow the DNS to skip the root query for subsequent .com queries). The use of a DNS cache is so significant that there are even caching-only DNS servers that do not act as a zone of authority for any domain.
If a Domain Name Server is unavailable then it would not be possible to access other machines. Therefore a backup server is configured as a fallback these are called secondary name servers as they can respond to the queries, but do not own the actual entries. The primary name server will push its configuration for any secondary name servers that it has configured as slaves.
In Linux the /etc/resolv.conf file provides details of which DNS servers it should use for DNS lookups.
The DNS process is discussed in RFC 1034 and RFC 1035.
If you don't have access to a DNS server, or would like to have additional entries not stored on a DNS server then these can be configured directly on the local computer. This can be implemented by adding entries to the /etc/hosts file. The host file is a list of hostnames and their IP addresses which allows them to be directly mapped. This can work for a small organisation or local network but if you had more than a handful of machines it is better to use a local DNS server.
If two machines are connected together as a point-to-point connection over a physical connection then they can communicate between each other directly. However once we start to communicate to computers on other networks, or over the Internet then routing is needed so that the data reaches the correct destination.
The devices that handle the directing of traffic are known as routers. These routers take an incoming packet and based upon the destination address send them through a different interface to either another router or to the end destination.
For a normal host computer all that is needed to handle the routing of all packets is to define the default gateway. The default gateway is a router directly attached to the same LAN segment as the host that knows how to route the packets on. Then for any address that is not locally held then it forwards the packet to the local router asking it to forward on to its destination. Alternatively for different networks the system could have multiple routes defined for different networks or hosts, or could participate in a dynamic routing protocol.
The router will then forward the packet on directly to the host network or to another router. Whenever a packet passes through a router this is called a hop.
There are three different types of routes. They could be implicit, static or dynamic. Implicit routes are where the configuration of TCP/IP indicates that the address is local to the machine (i.e. on the same physical LAN segment). Static are individually defined (often this will include a default route) and dynamic is where a networking protocol is used to identify the most appropriate route for different connections.
For static routes each entry in the routing table is added by using the route command. This is normally used to connect a host to its networks, but can be used for routers typically in smaller easy to manage networks.
It is possible that when a packet is sent using static routes that it will not neccessarily go the most direct route. For example if there are two routers on the LAN one of which goes directly to the host but the other would have to pass it to the other. This is illustrated below.

Figure 6: ICMP Redirect Example
Here we have Sys1 which is on network 0. There are two routers on the same LAN segment but Sys1 only has a default route pointing at Router 1. When Sys1 wants to communicate with Sys21 it first sends its request to Router1. Router1 realises that it has to forward it on to Router2 and that it would have been easier for Sys1 to have sent it directly there. It forwards the packet onto Router2 so that it reaches Sys21, but then also sends an ICMP redirect message to Sys1. Sys1 then adds a route in its routing table to send any packets for Sys21 to Router2. Then when Sys1 next needs to send a packet to Sys21 it can send it directly to Router2.
The operating system can handle these ICMP redirects or it can ignore them, depending upon the settings.
There are three dynamic routing protocols in general use. These are RIP (Routing Information Protocol), RIP 2 and OSPF (Open Shortest Path First). These work by routers constantly communicating to each other describing the network to each other. RIP uses the hop count (i.e. the number of routers the packet would travel through) to determine which route to send the packet through. OSPF is more sophisticated and allows the network administrator to set metrics to indicate a cost in using a certain route. This allows more expensive links (e.g. dialup connections) and for faster links to be preferred (e.g. those with higher bandwidth or shorter delay times).
These are all interior protocols as they are used within a network. To connect to other networks an exterior protocol is used and this is BGP (Border Gateway Protocol).
RIP is a simple protocol based on distance vectors. It uses a shortest path algorithm to determine the best route to the destination. This is measured in hops which is normally then number of gateways (routers) that are passed through before reaching a destination network. The routing daemon dynamically learns about the network using the RIP protocol and builds its own routing tables.
The line speed, reliability or cost are not taken into account when looking at the shortest link. There is a maximum hop count of 15 using RIP. Any destination over 15 hops away is considered to be an infinite number away and cannot be reached. This is a required feature of the RIP protocol as otherwise it would be possible to get routing loops where the routers through having out of date routes or static routes pass the packet around in a continuous circle.
Whilst suitable for small to medium networks this does not transfer well to a large network, due to its inflexibility and its low hop count.
The updates between routers are sent using UDP on port 520. When a router joins the network it broadcasts requesting for other routers to send their routing tables. Thereafter the router will advertise its tables to its neighbours every 30 seconds. Also if there is an update indicating a change in the network a router will send it immediately (almost).
RIP Version 2 (or RIP 2) provides some enhancements to the RIP protocol. This is documented in RFC 1723. The new features include:
Authentication - only accepts updates when provided with the correct password
Route Tag - Allows a tag value to be added to indicate that a link is external
Subnet Mask - Allows RIP to work in variably subnetted networks
Next Hop - Max RIP more flexible when used in a network with multiple routing protocols (i.e. OSPF and RIP)
Multicasting - Allow routers to multicast updates which is more efficient that using a broadcast.
If using OSPF or RIP 2 on a Linux system then the gated daemon needs to be started. For RIP 2 then the gated daemon is stated with an empty configuration file.
OSPF is a Link State protocol, therefore uses a a distributed map concept. The network map is a database help by each node and updates and performed by "flooding". All map updates must be secured.
In link state protocols each router is responsible for determining the identity of its neighbours. The router constructs a link state package (LSP) which lists its neighbours and the cost of the link. This is transmitted to all routers which then store the most recent LSP received from each router. The routers then construct a link state packet database from which the routes through the network are calculated.
The routers are normally grouped into areas. The routes in one area will summarise the information to send to the other areas. This limits the size of the link state database and the number of advertisements.
The OSPF protocol provides fast conversion and multiple metrics allowing for throughput, delay, cost and reliability to be taken into consideration. OSPF also allows for multiple paths to a destination providing immediate fallback in the event of a failure. Authorisation is provided for the routers (not available in RIP version 1). There is also no limit on network size with OSPF.
OSPF also allows for load balancing over links. This is more common in routers than in host machines.
So far we've been looking at IP version 4, which is currently the main addressing schemed used on the Internet. The number of remaining IPV4 addresses are running very low and the number of new devices that need IP addresses are increasing rapidly (eg tablets and mobile phones). IPv6 replaces the 32bit addressing scheme with one that is 128 bit long, which should provide as many addresses that will ever be required.
Computers with only an IPv4 address cannot communicate with another that has only an IPv6 address without first going through an intermediate node (proxy). It is however possible to have both an IPv4 and IPv6 address on the same computer using a dual-stack and it is possible to tunnel traffic over a different network.
IPv6 addresses are written in eight groups of four hexadecimal digits with each group seperated by a colon. For example: 2176:03df:1311:21da:0000:0000:33ad:0136. Where the are leading zeros then these can be omitted and one or more groups of consecutive zeros can be replaced by a double colon. Eg. the above can also be written as 2176:3df:1311:21da::33ad:136
RFC Documents
IP Subnet Mask Table Quick Reference
TCP and UDP Port Numbers (/etc/services) Quick Reference

